ASCL News
-
Tuesday started with Jeffrey Carver from the University of Alabama presenting What we have learned about using software engineering practices in scientific software. They took a multi-pronged approach to studying scientific software, from conducting surveys and workshop to direct interactions and case studies. From survey work, his team was able to group problems scientists were having with their own software into four main areas: rework, performance, regression (testing), and forgetting bugs. From this, they could see what software engineering practices might help with solving the problems.
Case studies brought numerous lessons to light; they found that the use of higher-level languages was low, performance competes with other goals, and external software use can be seen as risky. Workshops highlighted some of the differences between scientist programmers and software engineers and their domains. Scientist developers often lack formal software engineering expertise but have deep knowledge of their domains and are often the main users of their software. Quality goals are different, too; scientists would rather software not run than return an incorrect result. This project demonstrated that there is a need to eliminate the stigma associated with software engineering and that software engineers need to understand domain constraints and specific problems. PDF
Every presentation sparked lively Q&A and discussion, often throughout the presentation, and this one was no exception.


The next presentation was Engineering yt by Matthew Turk from NCSA at the University of Illinois at Urbana Champaign. He provided context and information on this well-cited community-developed project, discussed how the community was built, and its adoption of a code of conduct. YTEP, yt Enhancement Proposals, provide a method to manage suggestions for improving yt. Communication methods within the community are well thought out. The challenges of creating and managing the community sparked a lot of discussion; large software projects can have many things go wrong.


Discussion among the group made Matt's presentation run long, making it necessary to break for coffee before Matt's talk was done and then return to it after the break. The group was very engaged throughout the day; fortunately, the schedule accommodated the frequent discussions in every presention very well.
After Matt's talk, Caroline Jay (University of Manchester) and Robert Haines (Software Sustainability Institute) presented Software as academic output. They discussed software's role in research, when it can be a tool that enables research or the actual research itself, and how this is different depending on the discipline and the functionality of the software within the discipline and the role of the person using the software. They made the point that "Software isn't a separate thing -- software could exist without the paper; the paper couldn't exist without the software."

 Oh, there was much more goodness in this presentation, which was interrupted by lunch, than I have time to report, including The Horror, as it was termed -- the steps necessary for someone to replicate the computational work on one of the research projects this presentation covered -- and Robert's work on making this computational work software available in Docker. It also touched on the FAIR principles for computational research and academic software, and like the other presentations, generated lots of discussion, including conversations in the group on ethical considerations. PDF
Oh, there was much more goodness in this presentation, which was interrupted by lunch, than I have time to report, including The Horror, as it was termed -- the steps necessary for someone to replicate the computational work on one of the research projects this presentation covered -- and Robert's work on making this computational work software available in Docker. It also touched on the FAIR principles for computational research and academic software, and like the other presentations, generated lots of discussion, including conversations in the group on ethical considerations. PDF

The last formal presentation of the day, before the breakout workgroups, was by Claude Kirchner (INRIA) on the Software Heritage Project. He covered the rationale for this project, which includes the inconsiderate or malicious loss of code and the desire to preserve "our technical and scientific knowledge." The Software Heritage Project has set out to preserve all the software. Yes, you read that correctly: All the software. Fortunately, a version of the slides for this presentation are online so you can see them for yourself! The site is scheduled to go live next week and I look forward to seeing it.
After Claude's presentation, we went into breakout sessions.
 I joined a breakout session on getting a standing award for scientific contributions through software created. The other breakout sessions were on creating a research software engineering handbook and academic software project typology. All groups reported back before the day's session ended for dinner. Quite an informative, exciting, and productive day!
I joined a breakout session on getting a standing award for scientific contributions through software created. The other breakout sessions were on creating a research software engineering handbook and academic software project typology. All groups reported back before the day's session ended for dinner. Quite an informative, exciting, and productive day! -
I'm at Schloss Dagstuhl – Leibniz Center for Informatics for a week-long workshop on Engineering Academic Software. Some of the questions we are tackling have been discussed elsewhere, which we are taking into consideration as we talk about them here, and new questions were not only part of the seminar's original description, but are arising throughout the general and break-out sessions. I would say we're at the end of the first day but it continues on though it is past 10 PM, with a planned open and vibrant discussion on dogmas past and present. First up for discussion tonight was Agile project management; how do you feel about it? Is this a dogma that needs to be shot or embraced?
The hashtag to follow on Twitter is #dagstuhleas for the full-group discussions; the breakout sessions so far have been too intense for tweeting!
-
On Tuesday, October 27, the ASCL held a Birds of a Feather session at ADASS on Improving Software Citation and Credit. The session was opened with a brief presentation by Bruce Berriman, who reported on a Software Publishing Special Interest Group meeting held at the January 2015 AAS meeting and the ongoing work that has come out of that. I followed with a quick overview of other efforts to improve software credit and citation, not just in astronomy but across disciplines, after which Keith Shortridge moderated a lively discussion among the forty people present. The slides Bruce and I presented are now available online.
Previously, we shared resources for the session and the Google doc created during the session to capture some of the main points from the discussion.
-
The ASCL has organized a Birds of a Feather session (BoF) at ADASS to discuss improving software citation and credit to be held on Tuesday, October 27; the following links may be helpful for the discussion.
Astronomy-specific
Astronomy software citation examples and ideas (working [Google] document arising from AAS SPSIG discussion)Astronomy software indexing workshop
Cross-disciplinary
Workshop on Sustainable Software for Science: Practice and Experiences (WSSSPE)
Force11 Software Citation Working Group (Mission statement, member list, timeline, communications plan, etc. on GitHub)Center for Open Science's Transparency and Openness Promotion (TOP) Guidelines
Google doc created during the BoF session; anyone with the link can comment.
-
On Tuesday, January 6, the ASCL, AAS Working Group on Astronomical Software (WGAS), and the Moore-Sloan Data Science Environment at NYU sponsored a special session on software licenses, with support from the AAS. This subject was suggested as a topic of interest in the Astrophysics Code Sharing II: The Sequel session at AAS 223.
Frossie Economou from the LSST and chair of the WGAS opened the session with a few words of welcome and stressed the importance of licensing. I gave a 90-second overview of the ASCL before turning the podium over to Alberto Accomazzi from NASA/Astronomy Data System (ADS), who introduced the panel of speakers and later moderated the open discussion (opening slides), after which Frossie again took the podium for some closing remarks. The panel of six speakers discussed different licenses and shared considerations that arise when choosing a license; they also covered institutional concerns about intellectual property, governmental restrictions on exporting codes, concerns about software beyond licensing, and information on how much software is licensed and characteristics of that software. The floor was then opened for discussion and questions.

Discussion period moderated by Alberto Accomazzi Presentations
Some of the main points from each presentation are summarized below, with links to the slides used by the presenters.-
- Copy-left and Copy-right, Jacob VanderPlas (eScience institute, University of Washington)
Jake extolled everyone to always license codes, as in the US, copyright law defaults to "all privileges retained" unless otherwise specified. He pointed out that "free software" can refer to the freedoms that are available to users of the software. He covered the major differences between BSD/MIT-style "permissive" licensing and GPL "sticky" licensing while acknowledging that the difference between them can be a contentious issue.
slides (PDF)
- Copy-left and Copy-right, Jacob VanderPlas (eScience institute, University of Washington)
-
- University tech transfer perspective on software licensing, Laura L. Dorsey (Center for Commercialization, University of Washington)
Universities care about software licenses for a variety of reasons, Laura stated, which can include limiting the university's risk, respecting IP rights, complying with funding obligations, and retaining academic and research use rights. She also covered factors software authors may care about, among them receiving attribution, controlling the software, and making money. She reinforced the importance of licensing code and discussed the common components of a software license.
slides (PDF)
- University tech transfer perspective on software licensing, Laura L. Dorsey (Center for Commercialization, University of Washington)
-
- Relicensing the Montage Image Mosaic Engine, G. Bruce Berriman (Infrared Processing and Analysis Center, Caltech)
In last year's Astrophysics Code Sharing session, Bruce had discussed the limitations of the Caltech license under which the code Montage was licensed; since then, Montage has been relicensed to a BSD 3-Clause License. Following on the heels of Laura's discussion and serving as a case study for institutional concerns regarding software, Bruce related the reasons for and concerns about the relicensing, and discussed working with the appropriate office at Caltech to bring about this change.
slides (PDF)
- Relicensing the Montage Image Mosaic Engine, G. Bruce Berriman (Infrared Processing and Analysis Center, Caltech)
-
- Export Controls on Astrophysical Simulation Codes, Daniel Whalen (Institute for Theoretical Astrophysics, University of Heidelberg)

Restricted algorithms; image by Adam M. Jacobs Dan's presentation covered some of the government issues that arise from research codes, including why certain codes fall under export controls; a primary reason is to prevent the development of nuclear weapons.Dan also brought up how foreign intelligence agencies collect information and what specific simulations are restricted, and stated that Federal rules are changing, but slowly.
slides (PDF)
- Export Controls on Astrophysical Simulation Codes, Daniel Whalen (Institute for Theoretical Astrophysics, University of Heidelberg)
-
- Why licensing is just the first step, Arfon M. Smith (GitHub Inc.)
Arfon went beyond licensing in his presentation to discuss open source and open collaborations, and how GitHub delivers on a "theoretical promise of open source." He shared statistics on the growth of collaborative coding using GitHub, and demonstrated how a collaborative coding process can work and pointed out that through this exposed process, community knowledge is increased and shared. He challenged the audience to contemplate the many reasons for releasing a project and to ask themselves what kind of project they want to create.
slides (PDF)
- Why licensing is just the first step, Arfon M. Smith (GitHub Inc.)
-
- Licenses in the wild, Daniel Foreman-Mackey (New York University)
First, I have to note that Dan made it through 41 slides in just over the six minutes allotted for his talk, covering about seven slides/minute; I don't know whether to be more impressed with his presentation skills or the audience's information-intake abilities!
Percentage of licensed GitHub repos; image by Arfon Smith After declaring that he knows nothing about licensing, Dan showed us, and how, that he knows plenty about mining data and extracting information from it. From his "random" selection of 1.6 million GitHub repositories, he noted with some glee that 63 languages are more popular on GitHub than IDL is, the number of repositories with licenses have increased since 2012 to 17%, and that only 28,972 of the 1.6 million mentioned the license in the README file. Dan also determined the popularity of various licenses overall and by language and shared that information as well.
slides (PDF)
- Licenses in the wild, Daniel Foreman-Mackey (New York University)
Open Discussion
After Dan's presentation, Alberto Accomazzi opened the floor for discussion. Takeaway points included:- Discuss licensing with your institution; it's likely there is an office/personnel devoted to deal with these issues
- This office is likely very familiar with issues you bring to it, including who to refer you to when the issues are outside their purview
- "Friends don't let friends write their own licenses." IOW, select an existing license rather than writing your own
- License your code
- Let others know how you want your code cited/acknowledged
My thanks to David W. Hogg, Kelle Cruz, Matt Turk, and Peter Teuben for work -- which started last March! -- on developing the session, to Alberto for his excellent moderating and to Frossie for opening and closing it. My thanks also to the wonderful Jake, Laura, Bruce, Dan W, Arfon, and Dan F-M for presenting at this session, and to the Moore-Sloan Data Science Environment at NYU and AAS for their sponsorship.
Resources
Many resources on licensing, including excellent posts by Jake and Bruce, can be found here. -
-
Below, a list of informative, interesting (or both!) writings about software licensing; the ASCL doesn't necessarily agree with all positions in these articles, but we want to know what people are thinking even when we don't agree with them.
EUDAT License Wizard
http://www.eudat.eu/news/eudat-license-wizard-guides-you-through-legal-maze
http://ufal.github.io/lindat-license-selector/A Quick Guide to Software Licensing for the Scientist-Programmer
By Andrew Morin, Jennifer Urban, Piotr Sliz
http://www.ploscompbiol.org/article/info%3Adoi%2F10.1371%2Fjournal.pcbi.1002598Relicensing yt from GPLv3 to BSD
By Matthew Turk
http://blog.yt-project.org/post/Relicensing.htmlBest Practices for Scientific Computing
Greg Wilson, D. A. Aruliah, C. Titus Brown, Neil P. Chue Hong, Matt Davis, Richard T. Guy, Steven H. D. Haddock, Katy Huff, Ian M. Mitchell, Mark Plumbley, Ben Waugh, Ethan P. White, Paul Wilson
http://arxiv.org/abs/1210.0530v4The Whys and Hows of Licensing Scientific Code
By Jake VanderPlas
http://www.astrobetter.com/the-whys-and-hows-of-licensing-scientific-code/Licensing your code
ASCL blog post http://ascl.net/wordpress/?p=726 lists the following:Making Sense of Software Licensing
Choose a license
Open Source Initiative also offers information on licenses
White paper from the Software Freedom Law Center
Bruce Berriman’s post on relicensing MontageThe Gentle Art of Muddying the Licensing Waters
by Glyn Moody
http://blogs.computerworlduk.com/open-enterprise/2014/08/the-gentle-art-of-muddying-the-licensing-waters/index.htmSTM open license suggestions and aftermath
Open Access Licensing
Don’t Muddy the “Open” Waters: SPARC Joins Call for STM Association to Rethink New Licenses
Global Coalition of Access to Research, Science and Education Organizations calls on STM to Withdraw New Model Licenses
STM response to ‘Global Coalition of Access to Research, Science and Education Organisations calls on STM to Withdraw New Model Licenses’
New “open” licenses aren’t so openInteresting talk on ITAR
http://www.state.gov/e/stas/series/154211.htm
Discusses dual-use technologies, which is what codes are under ITAR. These are governed by the Wassenaar Arrangement. The countries that participate meet 3x/year to decide what restrictions to put on dual-use technologies. Dr. James Harrington was the speaker. Slides available on that page. -
This is an update on figures I've previously shared (most recently here). Currently, the ASCL indexes 977 codes. The percentage of these codes housed on social coding sites are:
GitHub: 8.1%
SourceForge: 4.2%
Code.Google: 2.8%
Bitbucket: 1.3%This gives us 16.4% of codes listed on the ASCL housed on a public social coding site, an increase since February of 5.4%, most of this from GitHub (up from 4.2% in February), though the percentages of four sites have increased.
As I said in February, I expect the percentage of codes on social coding sites will continue to grow, especially since GitHub's use is increasing quickly in the community. One factor some credit for this increase is that GitHub has made it easy to push code to Zenodo for archiving and DOI minting, and providing another way to cite code.*
As mentioned in my previous post, how codes are cited vary. Software citation will be the main topic at Tuesday's inaugural Software Publishing Special Interest Group meeting at AAS225, which will be held at 3:45 PM in 615 of the Convention Center. If you are at AAS this week, you are welcome to attend and I hope to see you there!
*It was reported at .Astronomy6 that "some astro journals won't even accept a DOI as a citation." I don't know which journals and hope someone will enlighten me; I would like to know the rationale for that stance and would gladly take this up with publishers.
-
One of the unconference sessions (proposed during the event) held at December's .Astronomy was on software citation, this subject having come up in an earlier session on improving credit for software.
Discussion and comments in the session inspired me to look at astronomy's current practices for citing software. Though not an exhaustive list, I looked in more than a dozen journals for citations for codes used in research, and below are some of the examples I gathered.
The most common way to cite software is to reference a paper describing the code. This is how, for example, the authors of yt would like that software cited, as shown from a recent MNRAS paper:
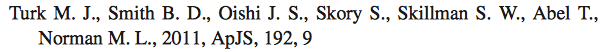
Sometimes a link to the website for a code is listed as a reference to it, as was done in a Classical and Quantum Gravity paper: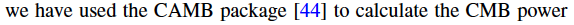
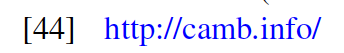
Conference proceedings are cited in some cases, as the citation below for WCSTools in an The Astrophysical Journal paper demonstrates:
ASCL entries can be cited, too, as shown in this citation for pynbody in a paper published in Physical Review D:
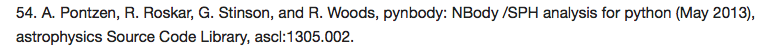 Someone -- I don't remember who -- reported that Google Scholar does not index mentions of codes, GitHub repos, etc. as citations, because they are not papers. An opinion tweeted out about this summed up the sentiment in the room pretty well! I plan to take this up with Google after the AAS meeting. Fortunately, ADS does index properly formatted software references; the only reference listed in this post that I didn't see captured by ADS was the URL for CAMB, which is not surprising (nor expected).
Someone -- I don't remember who -- reported that Google Scholar does not index mentions of codes, GitHub repos, etc. as citations, because they are not papers. An opinion tweeted out about this summed up the sentiment in the room pretty well! I plan to take this up with Google after the AAS meeting. Fortunately, ADS does index properly formatted software references; the only reference listed in this post that I didn't see captured by ADS was the URL for CAMB, which is not surprising (nor expected).A subsequent post will include additional information and a list of resources about software citation, to be posted before the first Special Interest Group on software publishing meeting scheduled at AAS225 that will be held on Tuesday, January 6, from 3:45 PM – 4:45 PM in 615 in the Convention Center. The main topic of this meeting will be software citation, and all interested parties are welcome to attend.
The journals below were part of my hunting grounds for software citations. Ever had a citation to software you used in research refused by a publication? If so, I'm interested in knowing the details; please share here or send them to editor@ascl.net. Thanks!
American Institute of Physics Proceedings
Astronomy & Astrophysics
Astronomy and Computing
The Astronomical Journal
The Astrophysical Journal
The Astrophysical Journal Supplement
Classical and Quantum Gravity
Icarus
Monthly Notices of the Royal Astronomical Society
Nature
Physical Review D
Proceedings of the SPIE
Publications of the Astronomical Society of Australia
Publications of the Astronomical Society of Japan
Publications of the Astronomical Society of the PacificAdditional screenshots of software citations:
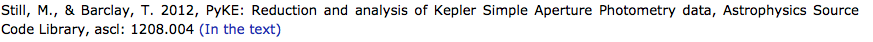




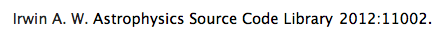
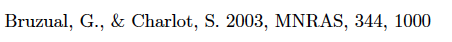
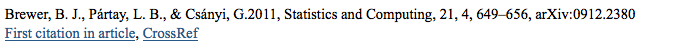
Formatting counts! Below, two citations for Turbospectrum, the first formatted in a way ADS can pick up and count the citation, the second one not.
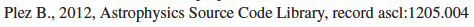
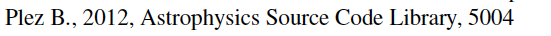
-
I'm delighted to offer the following guest post by Jonathan Petters, Data Management Consultant, Johns Hopkins Data Management Services, and thank him very much for it!
 In a recent discussion on preservation and sharing of research data, a few participants expressed their concern (paraphrased here) that “My research community doesn't know how to create a quality data management plan” and “We don't know how to evaluate data management plans.” The astronomy community explicitly requested a little guidance. We in Johns Hopkins University Data Management Services have developed a few resources, described below, of use in both developing and evaluating data management plans within all research disciplines, including astronomy.
In a recent discussion on preservation and sharing of research data, a few participants expressed their concern (paraphrased here) that “My research community doesn't know how to create a quality data management plan” and “We don't know how to evaluate data management plans.” The astronomy community explicitly requested a little guidance. We in Johns Hopkins University Data Management Services have developed a few resources, described below, of use in both developing and evaluating data management plans within all research disciplines, including astronomy.Funding agencies have long encouraged and expected that data and code used in the course of funded research be made available to those in the research discipline. NSF is an important funder of astronomical research that has such expectations (and the agency I will focus on here). A few years ago NSF began requiring data management plans as part of research proposal, in part to aid in the dissemination and sharing of research data and code. Following a February 2013 Office of Science and Technology Policy memo other US funding agencies are expected to follow suit with similar data management plan requirements, including the Department of Energy's Office of Science.
What does NSF say about writing and evaluating quality data management plans? A good overview of NSF data policies relevant for the AST community can be found in these slides from Daniel Katz, NSF). In general the National Science Foundation (NSF) states that data management will be defined by “the communities of interest.” The NSF AST-specific policy further states “MPS Divisions will rely heavily on the merit review process in this initial phase to determine those types of plan that best serve each community and update the information accordingly.” Neither statement is especially prescriptive and can leave researchers unclear as to what they should do.
Creating a plan
While effective research data management certainly has community- and discipline-specific attributes, there ARE aspects of effective data management that are generalizable across research disciplines. It is around these general aspects that we in Johns Hopkins University Data Management Services (JHUDMS) devised our Data Management Planning Questionnaire. We work through this questionnaire with researchers at Johns Hopkins to help them create effective data management plans.The Questionnaire is designed to comprehensively hit upon the important aspects of effective research data management (e.g. data inputs/outputs in the research, ethical/legal compliance, standards and formats used, intended sharing and preservation, PI restrictions on the use of the data). By answering the applicable questions in the document, removing the questions/front matter and connecting the answers in each section into paragraphs, a researcher would be well on their way to a quality, well thought-out data management plan.
Two relevant side-notes:
1.) For the Questionnaire we consider code and software tools as one 'kind' of research data; thus analysis or simulation codes used in the course of your proposed research should be included as a Data Product. While research code and research data generated or processed by code are clearly NOT the same, there are many similarities in managing the two. In both cases effective management should include consideration of documentation, licensing, formats, associated metadata, and upon what platform(s) the data or code could be shared.2.) Astronomy, as in other disciplines, conducts a substantial amount of research through large collaborations (e.g. surrounding HST or SDSS data). In these cases it is typical for investments in research data infrastructure to be made, and data policies/practices to be defined for those working with the data. Citing those policies and practices in a data management plan would be appropriate.

Evaluating a plan
To help researchers evaluate data management plans for their quality, my colleagues developed the Reviewer Guide and Worksheet for Data Management Plans (dotx). This Guide and Worksheet is a complement to our Questionnaire; it is a handy checklist by which a grant reviewer can determine whether a researcher thoroughly considered the important aspects of research data management.For those who researchers saying to themselves, “The Questionnaire and Reviewer Guide are nice, but PLEASE just tell me what to do!!!”, I found two tweets from the code sharing session at the latest (223rd) AAS meeting in January to be quite relevant (h/t August Muench and Lucianne Walkowicz):


I wholeheartedly agree with both tweets. It is up to the research community members to police and enforce the data management and sharing practices they would like to see in their community. That’s how peer review works! So the next time you review astronomical research proposals, look over the data management plans carefully and bring up relevant thoughts and concerns to the review panel.
Summing up
I hope the Data Management Planning Questionnaire and Reviewer Guide and Worksheet for Data Management Plans help you and other researchers in the astronomy community more fully develop expectations for data management and sharing practices. It’s likely your institution also has research data management personnel (like the JHUDMS at Hopkins) who are more than happy to help! -
Mozilla Science Lab, GitHub and Figshare team up to fix the citation of code in academia
The Mozilla Science Lab, GitHub and Figshare – a repository where academics can upload, share and cite their research materials – is starting to tackle the problem. The trio have developed a system so researchers can easily sync their GitHub releases with a Figshare account. It creates a Digital Object Identifier (DOI) automatically, which can then be referenced and checked by other people.Discussion of the above article on YCombinator
...it always make me cringe when privately held companies want to define an "open standard" for scientific citations that (surprise!) relies completely on their proprietary infrastructure. I still remember the case of Mendeley, which promised to build an open repository for research documents, and which is now a subsidiary of Elsevier, an organization that does not really embrace "open science", to put it mildly.Tool developed at CERN makes software citation easier
Researchers working at CERN have developed a tool that allows source code from the popular software development site GitHub to be preserved and cited through the CERN-hosted online repository Zenodo....
Now, people working on software in GitHub will be able to ensure that their code is not only preserved through Zenodo, but is also provided with a unique digital object identifier (DOI), just like an academic paper.Webcite
WebCite is an on-demand archiving system for webreferences (cited webpages and websites, or other kinds of Internet-accessible digital objects), which can be used by authors, editors, and publishers of scholarly papers and books, to ensure that cited webmaterial will remain available to readers in the future.DOIs unambiguously and persistently identify published, trustworthy, citable online scholarly literature. Right?
So DOIs unambiguously and persistently identify published, trustworthy, citable online scholarly literature. Right? Wrong.
The examples above are useful because they help elucidate some misconceptions about the DOI itself, the nature of the DOI registration agencies and, in particular issues being raised by new RAs and new DOI allocation models.


