ASCL News
-
 Our science depends on public digital resources, including data archives, software repositories, computational infrastructures, and catalogs. Recent actions by non-scientists have led to the loss of important digital resources in other fields, and even astrophysics assets may face uncertain futures. This poster invites astronomers to reflect on how dependent our research is on shared resources and which of these may be vulnerable to loss. It also asks what actions we can take to safeguard these resources to ensure they remain secure for the future.
Our science depends on public digital resources, including data archives, software repositories, computational infrastructures, and catalogs. Recent actions by non-scientists have led to the loss of important digital resources in other fields, and even astrophysics assets may face uncertain futures. This poster invites astronomers to reflect on how dependent our research is on shared resources and which of these may be vulnerable to loss. It also asks what actions we can take to safeguard these resources to ensure they remain secure for the future.Download (PDF)
-
Discussion last week with IAU GA attendees, including software authors and data and journal editors, resulted in a proposal to hold an unconference session on improving software citation, this intended to be a discussion that results in ideas that can be implements. The session was held on Tuesday, August 13 at 12:30 PM SAST.
This post is to capture resources that may be useful for this discussion and subsequent output. The list will grow over the next few days, so check back for additional information.
Session video
This session was recorded as part of the day's Unconference events and can be found on YouTube.Articles
Ten simple rules for recognizing data and software contributions in hiring, promotion, and tenure
Research Software Engineers: Career Entry Points and Training Gaps
Characterizing Role Models in Software Practitioners' Career: An Interview Study
Research Software Science: Expanding the Impact of Research Software Engineering -
The following guest post is by John Wallin, the Director of the Computational and Data Science Ph.D. Program and Professor of Physics and Astronomy at Middle Tennessee State University

Dr. John Wallin Since the 1960s, scientific software has undergone repeated innovation cycles in languages, hardware capabilities, and programming paradigms. We have gone from Fortran IV to C++ to Python. We moved from punch cards and video terminals to laptops and massively parallel computers with hundreds to millions of processors. Complex numerical and scientific libraries and the ability to immediately seek support for these libraries through web searches have unlocked new ways for us to do our jobs. Neural networks are commonly used to classify massive data sets in our field. All these changes have impacted the way we create software.
In the last year, large language models (LLM) have been created to respond to natural language questions. The underlying architecture of these models is complex, but the current generation is based on generative pre-trained transformers (GPT). In addition to the base architecture, they have recently incorporated supervised learning and reinforcement learning to improve their responses. These efforts resulted in a flexible artificial intelligence system that can help solve routine problems. Although the primary purpose of these large language models was to generate text, it became apparent that these models could also generate code. These models are in their infancy, but they have been very successful in helping programmers create code snippets that are useful in a wide range of applications. I wanted to focus on two applications of the transformer-based LLM - ChatGPT by OpenAI and GitHub Copilot.
ChatGPT is perhaps the most well-known and used LLM. The underlying GPT LLM was released about a year ago, but a newer interactive version was made publicly available in November 2022. The user base exceeded a million after five days and has grown to over 100 million. Unfortunately, most of the discussion about this model has been either dismissive or apocalyptic. Some scholars have posted something similar to this:
"I wanted to see what the fuss is about this new ChatGPT thing, so I gave a problem from my advanced quantum mechanics course. It got a few concepts right, but the math was completely wrong. The fact that it can't do a simple quantum renormalization problem is astonishing, and I am not impressed. It isn't a very good "artificial intelligence" if it makes these sorts of mistakes!"
The other response that comes from some academics:
"I gave ChatGPT an essay problem that I typically give my college class. It wrote a PERFECT essay! All the students are going to use this to write their essays! Higher education is done for! I am going to retire this spring and move to a survival cabin in Montana to escape the cities before the machine uprising occurs."
 Of course, neither view is entirely correct. My reaction to the first viewpoint is, "Have you met any real people?" It turns out that not every person you meet has advanced academic knowledge in your subdiscipline. ChatGPT was never designed to replace grad students. A future version of the software may be able to incorporate more profound domain-specific knowledge, but for now, think of the current generation of AIs as your cousin Alex. They took a bunch of college courses and got a solid B- in most of them. They are very employable as an administrative assistant, but you won't see them publish any of their work in Nature in the next year or two. Hiring Alex will improve your workflow, even if they can't do much physics.
Of course, neither view is entirely correct. My reaction to the first viewpoint is, "Have you met any real people?" It turns out that not every person you meet has advanced academic knowledge in your subdiscipline. ChatGPT was never designed to replace grad students. A future version of the software may be able to incorporate more profound domain-specific knowledge, but for now, think of the current generation of AIs as your cousin Alex. They took a bunch of college courses and got a solid B- in most of them. They are very employable as an administrative assistant, but you won't see them publish any of their work in Nature in the next year or two. Hiring Alex will improve your workflow, even if they can't do much physics.The apocalyptic view also misses the mark, even if the survival cabin in Montana sounds nice. Higher education will need to adapt to these new technologies. We must move toward more formal proctored evaluations for many of our courses. Experiential and hands-on learning will need to be emphasized, and we will probably need to reconsider (yet again) what we expect students to take away from our classes. Jobs will change because of these technologies, and our educational system needs to adapt.
Despite these divergent and extreme views, generative AI is here to stay. Moreover, its capabilities will improve rapidly over the next few years. These changes are likely to include:
- Access to live web data and current events. Microsoft's Bing (currently in limited release) already has this capability. Other engines are likely to become widely available in the next few months.
- Improved mathematical abilities via linking to other software systems like Wolfram Alpha. ChatGPT makes mathematical errors routinely because it is doing math via language processing. Connecting this to symbolic processing will be challenging, but there have already been a few preliminary attempts.
- Increased ability to analyze graphics and diagrams. Identifying images is already routine, so moving to understand and explaining diagrams is not an impossible extension. However, this type of future expansion would impact how the system analyzes physics problems.
- Accessing specialized datasets such as arXiv, ADS, and even astronomical data sets. It would be trivial to train GPT3.5 on these data sets and give it domain-specific knowledge.
- Integrating the ability to create and run software tools within the environment. We already have this capability in GitHub Copilot, but the ability to read online data and immediately do customized analysis on it is not out of reach for other implementations as well.
Even without these additions, writing code with GitHub Copilot is still a fantastic experience. Based on what you are working on, your comments, and its training data, it attempts to anticipate your next line or lines of code. Sometimes, it might try to write an entire function for you based on a comment or the name of the last function. I've been using this for about five months, and I find it particularly useful when using library functions that are a bit unfamiliar. For example, instead of googling how to add a window with a pulldown menu in python, you would write a comment explaining what you want to do, and the code will be created below your comment. It also works exceptionally well solving simple programming tasks such as creating a Mandelbrot set or downloading and processing data. I estimate that my coding speed for solving real-world problems using this interface has tripled.
However, two key issues need to be addressed when using the code: authorship and reliability.
When you create a code using an AI, it goes through millions of lines of public domain code to find matches to your current coding. It predicts what you might be trying to do based on what others have done. For simple tasks like creating a call to a known function in a python library, this is not likely to infringe on the intellectual property of someone's code. However, when you ask it to create functions, it is likely to find other codes that accomplish the task you want to complete.
 For example, there are perhaps thousands of examples of ODE integrators in open-source codes. Asking it to create such a routine for you will likely result in inadvertently using one of those codes without knowing its origin.
For example, there are perhaps thousands of examples of ODE integrators in open-source codes. Asking it to create such a routine for you will likely result in inadvertently using one of those codes without knowing its origin.The only thing of value we produce in science is ideas. Using someone else's thoughts or ideas without attribution can cross into plagiarism, even if that action is unintentional. Code reuse and online forums are regularly part of our programming process, but we have a higher level of awareness of what is and isn't allowed when we are the ones googling the answer. Licensing and attribution become problematic even in a research setting. There may be problems claiming a code is our intellectual property if it uses a public code base. Major companies have banned ChatGPT from being used for this reason. At the very least, acknowledging that you used an AI to create the code seems like an appropriate response to this challenge. Only you can take responsibility for your code, but explaining how it was developed might help others understand its origin.
The second issue for the new generation of AI assistants is reliability. When I asked ChatGPT to write a short biographical sketch for "John Wallin, a professor at Middle Tennessee State University," I found that I had received my Ph.D. from Emory University. I studied Civil War and Reconstruction era history. It confidently cited two books that I had authored about the Civil War. All of this was nonsense created by a computer creating text that it thought I wanted to read.
It is tempting to think that AI-generated code would produce correct results. However, I have regularly seen major and minor bugs within the code it has generated. Some of the mistakes can be subtle but could lead to erroneous results. Therefore, no matter how the code is generated, we must continue to use validation and verification to determine if we both have a code that correctly implements our algorithms and have the correct code to solve our scientific problem.
Both authorship and reliability will continue to be issues when we teach our students about software development in our fields. At the beginning of the semester, I had ChatGPT generate "five group coding challenges that would take about 30 minutes for graduate students in a Computational Science Capstone course." When I gave them to my students, it took them about 30 minutes to complete. I created solutions for ALL of them using GitHub Copilot in under ten minutes. Specifying when students can and can't use these tools is critical, along with developing appropriate metrics for evaluating their work when using these new tools. We also need to push students toward better practices in testing their software, including making testing data sets available when the code is distributed.
Sharing your software has never been more important, given these challenges. Although we can generate codes faster than ever, the reproducibility of our results matters. Your methodology's only accurate description is the code you used to create the results. Publishing your code when you publish your results will increase the value of your work to others. As the abilities of artificial intelligence improve, the core issues of authorship and reliability still need to be verified by human intelligence.
Addendum: The Impact of GPT-4 on Coding and Domain-Specific Knowledge
Written with the help of GPT-4; added March 20, 2023Since the publication of the original blog post, there have been significant advancements in the capabilities of AI-generated code with the introduction of GPT-4. This next-generation language model continues to build on the successes of its predecessors while addressing some of the limitations that were previously observed.
One of the areas where GPT-4 has shown promise is in its ability to better understand domain-specific knowledge. While it is true that GPT-4 doesn't inherently have access to specialized online resources like arXiv, its advanced learning capabilities can be utilized to incorporate domain-specific knowledge more effectively when trained with a more specialized dataset.
Users can help GPT-4 better understand domain-specific knowledge by training it on a dataset that includes examples from specialized sources. For instance, if researchers collect a dataset of scientific papers, code snippets, or other relevant materials from their specific domain and train GPT-4 with that data, the AI-generated code would become more accurate and domain-specific. The responsibility lies with the users to curate and provide these specialized datasets to make the most of GPT-4's advanced learning capabilities.
By tailoring GPT-4's training data to be more suited to their specific needs and requirements, users can address the challenges of authorship and reliability more effectively. This, in turn, can lead to more efficient and accurate AI-generated code, which can be particularly valuable in specialized fields.
In addition to the advancements in domain-specific knowledge and coding capabilities, GPT-4 is also set to make strides in the realm of image analysis. Although not directly related to coding, these enhancements highlight the growing versatility of the AI engine. While the image analysis feature is not yet publicly available, it is expected to be released soon, allowing users to tap into a new array of functionalities. This expansion of GPT-4's abilities will enable it to understand and interpret images, diagrams, and other visual data, which could have far-reaching implications for various industries and applications. As GPT-4 continues to evolve, it is crucial to recognize and adapt to the ever-expanding range of possibilities that these AI engines offer, ensuring that users can leverage their full potential in diverse fields.
With the rapid advancements in AI capabilities, it is essential for researchers, educators, and developers to stay informed and adapt to the changes that GPT-4 and future models bring. As AI-generated code becomes more accurate and domain-specific, the importance of understanding the potential benefits, limitations, and ethical considerations of using these tools will continue to grow.
-
In June, I was invited to participate in a one-day workshop as a member of an expert panel for the The Open Source Software Health Index Project. The subject of software citation came up at lunch with other panel members, and someone suggested that because of the limit on references in prestigious publications, citations for software may be dropped to make room for article citations. This surprised me, since I know that several highly-regarded journals have published articles on the importance of research software, have edited their author guidelines to include more and better information on citing software properly, and have improved how citations to ASCL entries, for example, are treated to ensure their proper capture and tracking by indexers.
So I wrote to editors at a number of prestigious publications such as Nature and Science to ask whether their publications might consider exempting software citations from the reference limits. The prompt replies stated that there is no need to do so: there is room for essential references, and even if there are (soft) limits on the number of references in the main text in the print journal, they are unlimited in the online supplementary materials, the reference list appears in full on the website (the version that has the most readers), and all are picked up (or at least made available for ingestion) as citations in bibliographic databases.
Here is a case in point: this Science paper was printed with a limited number of references, but all 113 appear in the online version, and 92 of them were captured by ADS. Those not captured by ADS include one of the four software references, which is only a link to a website, and other references that are similarly not formatted well for tracking or are to resources ADS does not ingest.


I'm very pleased -- and relieved! -- to know the commitment to have code cited well carries over to practice and that limiting citations in print format, when this might occur, does not appear to inhibit nor restrict software citation.
-
The ASCL has once again partnered with others on a Special Session at EWASS. This year's Special Session (SS34) is titled Understanding data: Visualisation, machine learning, and reproducibility, and will be held on Tuesday, 25 June, in Room 3. Not at EWASS? Follow the session on Twitter at #ewass19ss34.
Full information, including abstracts for the presentations listed below, can be found in the detailed interactive program; look for the sessions in yellow and labeled SS34a, SS34b, and SS34c.
Tuesday, 25 June, 9:00 in Room 3, chaired by Rein Warmels
Reproducibility in computer-aided research by Konrad Hinsen
Publishing associated data: Challenges & opportunities by Pierre Ocvirk
FAIR data in astronomy by Mark Allen
Template for reproducible, shareable & achievable research by Mohammad Akhlaghi
These talks are followed by an open discussion moderated by David Valls-Gabaud.Tuesday, 25 June, 14:30 in Room 3, chaired by Amruta Jaodand
High-performance machine learning in Astrophysics by Simon Portegies Zwart
Machine learning for the SKA by Anna Scaife
SuperNNova: Open-source, deep learning photometric time-series classifier by Anais Möller
Transfer learning for radio galaxy classification by Hongming Tang
Unsupervised classification of galaxy spectra and interpretability by Didier Fraix-burnetTuesday, 25 June, 16:30 in Room 3, chaired by John Wenskovitch
Visual Analytics of Data in Astronomy by Johanna Schmidt
Visual analytics algorithms for multidimensional astronomical data by Dany Vohl
Pulsar to Person (P2P): Data Visualization & Sonification to Experience the Universe by John Wenskovitch
Lightning talks for e-Posters
These talks are followed by an open discussion moderated by the session chair.This Special Session was organized by:
Rachael Ainsworth (UManchester)
Mohammad Akhlaghi (Instituto De Astrofísica De Canarias)
Amruta Jaodand (ASTRON)
David Valls-Gabaud (Observatoire de Paris)
Rein Warmels (ESO)
John Wenskovitch (Virginia Tech)
Alice Allen (ASCL/UMD) -
I spent two days last week at the Open Digital Infrastructure in Astrophysics meeting at the Kavli Institute for Theoretical Physics (KITP) at UC Santa Barbara. This meeting featured presentations on open-knowledge digital infrastructure projects, the communities around them, their metrics for success, funding, diversity efforts, and plans for sustainability. Yeah, we're talking code, a lot of code, and code projects, too, from AstroPy to yt, and data, and efforts that support openness and research transparency.
Open data presentations were given on:
STScI data, which includes JWST, Hubble, and PanSTARRS data, and the discovery and analysis software for these archives, by Arfon Smith
SDSS Data Infrastructure, by Joel Brownstein
LSST Transients data, by Federica Bianco
Open gravitational wave data and software tools for these data, by Duncan BrownThese software projects were represented at the meeting:
 Astropy, by Kelle Cruz
Astropy, by Kelle Cruz
ATHENA++, by Jim Stone
Einstein Toolkit, by Philipp Mösta
emcee, by Daniel Foreman-Mackey
GYRE, by Rich Townsend
JETFIT, by Andrew Macfadyen
MESA Project, by Frank Timmes
TOM Toolkit and the AEON Network, by Rachel Street
yt, by Matt TurkOther open digital resources presented were:
Journal of Open Source Software, by Arfon Smith
R astrostatistics, by Gwendolyn Eadie
Astrophysics Source Code Library, by yours trulyThe meeting hashtag was #OpenAstroInfra, and many of the presentations were live tweeted. They were also video recorded and the podcasts are available on the KITP media page for the meeting, as are most of the slide decks. Participants of the co-located "Better Stars, Better Planets: Exploiting the Stellar-Exoplanetary Synergy" and "The New Era of Gravitational-Wave Physics and Astrophysics" programs were encouraged to attend, and we had a raven or two trying to have lunch with us as well.
Each of the presentations had about 15 minutes devoted to questions and discussion about the project highlighted. In two of these discussion sessions, the presenters were asked whether they were concerned about "improper use" of a code; sometimes people who are not well-schooled in the theory or science underlying a software package will use the code incorrectly, arriving at results that are dodgy, or downright wrong, and in a few cases (I know of only one), have then claimed the software is in error. This fear has been given as the reason some software authors do not release their code. I was cheering in my head with Jim Stone's response to this question the first time it came up; he stated that there is so much benefit to making the code available that a potential improper use should not stop release. (YES!!!) He further went on to say, as did others in the room, that science will correct the record (YES!!!!!). I could not agree more with these replies, and it was great to hear these sentiments from others.
This was my first visit to KITP, and what a wonderful introduction to the institution it was! So many excellent projects, and so much exciting work being done in the open! My thanks to organizers Frank Timmes, Lars Bildsten, and Rich Townsend for inviting the ASCL to participate, and to the Sloan and Ford Foundations for funding the meeting.
-
MONDAY, 7 JANUARY 2019
Splinter Meeting: An Open Discussion on Astronomy Software
2:00 pm - 3:30 pm
Room 4C-4, Washington State Convention CenterThe Astrophysics Source Code Library (ASCL) has organized a Splinter Meeting at January’s AAS meeting. The session, An Open Discussion on Astronomy Software, is offered in recognition of the ASCL's 20th anniversary.
Though progress has been made on various fronts, there is still work to be done to improve how astronomers (and other scientists) design, write, share, publish, maintain, archive, and receive credit, recognition, and steady positions for software. This open discussion on software will cover issues, topics, and questions attendees would like addressed, with a panel of software authors to reflect on the topics along with attendees. The session could potentially cover topics such as the sustainability of core astronomical software, whether astronomy should have a Decadal Plan for software and whether publishing need to change, and if so, how? Please submit the issues and questions you would like to see addressed this Google document (https://tinyurl.com/AAS233SWDiscussion). The panel members are:
Megan Ansdell, University of California Berkeley
Rory Barnes, University of Washington
C.E. Brasseur, Space Telescope Science Institute (@cebrasseur)
Tess Jaffe, University of Maryland/NASA Goddard Space Flight Center
Mario Juric, University of Washington (@mjuric)
Amanda Kepley, National Radio Astronomy Observatory (@aakepley)
Rocio Kiman, City University of New York (@rociokiman)The meeting will be moderated by Alice Allen (ASCL/UMD) and will end with celebratory food (yes, there will be cake!!) for the ASCL’s 20th anniversary.
-
Now that I've written extensively about days 2-4, I am cycling back to give day 1 its due, but first will say the sharing started on Sunday June 19 as people arrived for both the week-long Engineering Academic Software Perspectives Workshop and the three-day Information-centric Networking and Security Seminar; cake and coffee is available upon arrival, which gives folks an opportunity to meet, and conversation between participants in both workshops flowed easily. A
 group of us decided to walk to the old castle ruins on the hill -- up many steps -- and it was on this little jaunt that I learned firsthand about stinging nettles (having only read about them before) with Andrei Chiș providing most of the hands-on instruction. He and I experimented with different nettles to see which produced the greatest stinging/welts; oh, the things we do for science! Those who had been unwilling victims of the plants provided more data points, and our quick survey leads us to suspect that the more mature the plant, the greater its "don't touch!" defenses.
group of us decided to walk to the old castle ruins on the hill -- up many steps -- and it was on this little jaunt that I learned firsthand about stinging nettles (having only read about them before) with Andrei Chiș providing most of the hands-on instruction. He and I experimented with different nettles to see which produced the greatest stinging/welts; oh, the things we do for science! Those who had been unwilling victims of the plants provided more data points, and our quick survey leads us to suspect that the more mature the plant, the greater its "don't touch!" defenses.On Monday morning, we started with lightning introductions. We had been asked to create two slides, one on our relevant background and another on our interests for future use; a list of workshop participants and intro slides are available online.
 Next came presentations; first up was Dan Katz to talk about WSSSPE (Working towards Sustainable Software for Science: Practice and Experience), pronounced "wispy." He shared the history of the organization, noting that three large annual meetings had been held, with several smaller interim meetings also having taken place. WSSSPE's progression was to first identify challenges regarding software and best practices for sustainability, then to discuss solutions and ways to enable change, and then at WSSSPE3, to take action and encourage people to work in groups to put into practice the identified solutions. Katz's presentation included an overview of each of the WSSSPE working groups and the progress each group has made. Some of the working groups overlapped with efforts taking place elsewhere; the Software Credit Working Group, for example, shared much in common with Force11's Software Citation Working Group, so the decision was made to work on combining the two groups (which was successful) and for members to work on the Software Citation Principles that were being developed (which was also successful).
Next came presentations; first up was Dan Katz to talk about WSSSPE (Working towards Sustainable Software for Science: Practice and Experience), pronounced "wispy." He shared the history of the organization, noting that three large annual meetings had been held, with several smaller interim meetings also having taken place. WSSSPE's progression was to first identify challenges regarding software and best practices for sustainability, then to discuss solutions and ways to enable change, and then at WSSSPE3, to take action and encourage people to work in groups to put into practice the identified solutions. Katz's presentation included an overview of each of the WSSSPE working groups and the progress each group has made. Some of the working groups overlapped with efforts taking place elsewhere; the Software Credit Working Group, for example, shared much in common with Force11's Software Citation Working Group, so the decision was made to work on combining the two groups (which was successful) and for members to work on the Software Citation Principles that were being developed (which was also successful).Katz also shared lessons learned from WSSSPE3 -- what had worked, what could have worked better, and what didn't work. He outlined what is planned for WSSSPE4 (taking place this September in Manchester), listing two tracks for the event: Building a sustainable future for open-use research software, which will concentrate on defining the future of open-use scientific software and initiating plans to arrive at this future; and Practices and experiences in sustainable software, which will concentrate on improving current practices. Katz concluded his talk by sharing links to the reports for WSSSPE1, WSSSPE2, and WSSSPE3 and the social media sites. PDF
The next presentation, Supporting Research Software Engineering, was by Mike Croucher. His talk focused on his work as an Engineering and Physical Sciences Research Council (EPSRC) Research Software Engineering Fellow; he is one of only seven to be awarded this new fellowship. He helps scientists improve their software in various ways, such as making it faster, more reliable/robust/user friendly, and more sustainable. (Now that I've typed that, Harder, Better, Faster, Stronger is playing on the radio in my head.) This has to be done carefully, for as Croucher put it:
 The phrase "do computer science to them" was echoed throughout the rest of the workshop; this idea -- acknowledgement of that fear -- seemed to resonate with many.
The phrase "do computer science to them" was echoed throughout the rest of the workshop; this idea -- acknowledgement of that fear -- seemed to resonate with many.Croucher shared some of the outreach and education activities he's been involved with, one of which was a (gentle) self-paced R tutorial held in a café. Volunteer facilitators walked around to answer questions, clarify information, and unstick people who got stuck and the session was a rousing success, so much so that there are now requests and expectations that more will be held!
It was acknowledged at the beginning of the day that academic software faces many challenges; Croucher's presentation covered some of them, and included this stark slide:
 followed by:
followed by: He also mentioned the lack of funding for software activities, that soft-money researchers are discriminated against in favor of tenure-track and tenured faculty, and other issues. Oooo, he got a great discussion going with these and other points! In the active discussion, Cecilia Aragon made the point that we need to stop calling software "infrastructure," as software has intellectual content.
He also mentioned the lack of funding for software activities, that soft-money researchers are discriminated against in favor of tenure-track and tenured faculty, and other issues. Oooo, he got a great discussion going with these and other points! In the active discussion, Cecilia Aragon made the point that we need to stop calling software "infrastructure," as software has intellectual content.
 Though there are challenges, it's not all bad -- things are improving. The Software Sustainability Institute is funded by several organizations, the UK's Engineering and Physical Sciences Research Council (EPSRC) has recognized the importance of software through funding of the Research Software Engineers, and a Horizon 2020 project to provide "substantial funding" for open source maths research software. Croucher's vision of the future includes core-funded research software engineers and a hope for tenure awarded on the basis of software contributions. He closed his excellent presentation with concrete steps for changing the perception of software engineering and leading a change in culture. Slides
Though there are challenges, it's not all bad -- things are improving. The Software Sustainability Institute is funded by several organizations, the UK's Engineering and Physical Sciences Research Council (EPSRC) has recognized the importance of software through funding of the Research Software Engineers, and a Horizon 2020 project to provide "substantial funding" for open source maths research software. Croucher's vision of the future includes core-funded research software engineers and a hope for tenure awarded on the basis of software contributions. He closed his excellent presentation with concrete steps for changing the perception of software engineering and leading a change in culture. SlidesAfter a coffee break, the last presentation of the morning was given by Christoph Becker on Sustainability design. He covered the challenges of sustainability, and referred to the "sustainability debt"
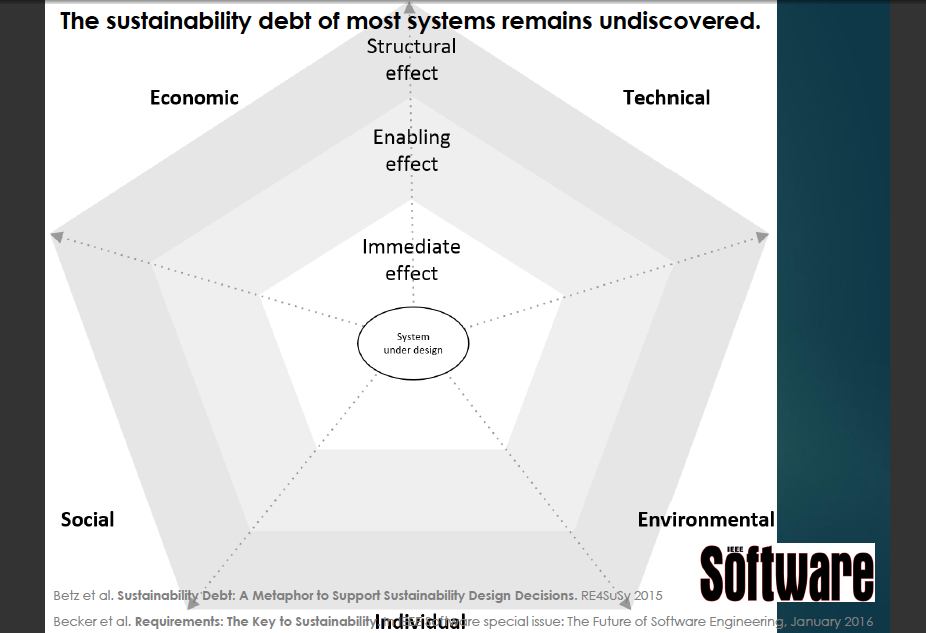 that is mostly unknown for most systems. The effects of sustainability (or lack thereof) can be considered from several angles; one way to look at this debt is across economic, technical social, environmental, and individual aspects, and whether it has an immediate, enabling, or structural effect. The concerns about sustainability have inspired the Karlskrona Manifesto for Sustainability Design, which seeks to address sustainability across different aspects and widening effects. The Manifesto identifies eleven "misperceptions and counterpoints", seeks to correct or mitigate them, and educate and advocate for a constructive approach to enabling a paradigm shift.
that is mostly unknown for most systems. The effects of sustainability (or lack thereof) can be considered from several angles; one way to look at this debt is across economic, technical social, environmental, and individual aspects, and whether it has an immediate, enabling, or structural effect. The concerns about sustainability have inspired the Karlskrona Manifesto for Sustainability Design, which seeks to address sustainability across different aspects and widening effects. The Manifesto identifies eleven "misperceptions and counterpoints", seeks to correct or mitigate them, and educate and advocate for a constructive approach to enabling a paradigm shift.  Becker is particularly interested in studying how people decide on the trade-offs they make when designing software, and using the insight gleaned to develop and implement methods and tools for making better choices. PDF
Becker is particularly interested in studying how people decide on the trade-offs they make when designing software, and using the insight gleaned to develop and implement methods and tools for making better choices. PDFAfter Becker's talk, we broke for lunch, then went into four breakout sessions for a good part of the afternoon; the four selected by participants from the many that had been proposed were:
- Academic software project typology
- Examining sustainability for a particular project
- Making the intellectual content of software visible
- Empirical survey of software practices in a domain
After working in our breakout sessions, we came back together to report on our progress. Wow, was there a lot of discussion! Everyone was very engaged in listening to, commenting on, and discussing the reports from the different groups. It was a very exciting afternoon, and discussion continued right up until we were forced to break for dinner.
As previously reported, we had a discussion in the evening as well. Monday was an excellent start to an outstanding week!
-
The morning of Day 4 of the Engineering Academic Software workshop opened with the mighty James Howison talking about the outputs expected from our work this week; these include a report of the meeting, the manifesto mentioned in my previous blog post, a draft document offering guidance for tenure committees on evaluating software contributions, a draft workplan for writing a proposal to establish an award for software contributions, a table of contents for a research software engineering handbook, and a sustainability debt use case, these last four from breakout session work.
The two talks on this morning might well be billed the Battle of Cool Places to Work. First up was Cecilia Aragon from the University of Washington on eScience Institute Initiatives. This work grew out of the realization that people were drowning in data, leading to the Moore/Sloan Data Science Environment, a $37.8M initiative at UCB, NYU, and UW.
 The eScience Institute has a multi-pronged approach set up around science theme areas with bridges to data science methodologies; this sets up a cycle wherein research needs generate new methodologies, which enable more science. Two new roles were established, Data Science Fellows and Data Scientists. They also set up education and training, including workshops and bootcamps for data science, such as Software Carpentry and Astro Hack Week and a seminar series. They offer a new MS in data science that is interdisciplinary, involving six departments, and innovative, with a social science component that includes a human-centered viewpoints and ethics. This MS program is designed for working professionals, provides a rigorous technical program in statistics and computer science, and has evening courses and allows full or part time attendance.
The eScience Institute has a multi-pronged approach set up around science theme areas with bridges to data science methodologies; this sets up a cycle wherein research needs generate new methodologies, which enable more science. Two new roles were established, Data Science Fellows and Data Scientists. They also set up education and training, including workshops and bootcamps for data science, such as Software Carpentry and Astro Hack Week and a seminar series. They offer a new MS in data science that is interdisciplinary, involving six departments, and innovative, with a social science component that includes a human-centered viewpoints and ethics. This MS program is designed for working professionals, provides a rigorous technical program in statistics and computer science, and has evening courses and allows full or part time attendance.  They have set up guidelines for reproducibility and offer help to people to improve this aspect of their work; eScience institute data scientists and others participate in a "drop-in" office hours program. They foster working relations with their working space and culture; people sit side-by-side to work on a problem. They see sharing a physical space as essential for data science and growing research software collaborations.
They have set up guidelines for reproducibility and offer help to people to improve this aspect of their work; eScience institute data scientists and others participate in a "drop-in" office hours program. They foster working relations with their working space and culture; people sit side-by-side to work on a problem. They see sharing a physical space as essential for data science and growing research software collaborations.Aragon discussed the integration of ethnography (a qualitative field-based technique originally from anthropology that enables study of underlying patterns and themes) and evaluation into a wide range of the data science environment. Ethnography research tries to answer questions such as Who does data science?, How are they networked?, and What forms of social interaction do they use? Ethnographers at UW work with members of the community to interpret observations and to provide feedback on what works and what doesn't. She reports they have had a lot of success with "applied ethnography".
She also discussed their data science incubator program, which was the precursor to the Data Science for Social Good program. They looked for high-impact data-intensive science projects that would benefit from quarter-long sprints of expertise, and had projects outlive the incubator, getting advances in both the science and the software and generating publishable
 results for both. One project was to try to solve problem of homelessness in Seattle. It involved bringing data about homelessness into more manageable form and analyzing it to see what worked, conducting analysis to identify predictors of permanent housing, and looking for successful outcomes. Another project, Open Sidewalks, created sidewalk maps for low-mobility citizens to show the curb cuts are.
results for both. One project was to try to solve problem of homelessness in Seattle. It involved bringing data about homelessness into more manageable form and analyzing it to see what worked, conducting analysis to identify predictors of permanent housing, and looking for successful outcomes. Another project, Open Sidewalks, created sidewalk maps for low-mobility citizens to show the curb cuts are.Aragon discussed the marketing that they do; they talk to a lot of people, and this has helped with engagement. They actively look for ways to build relationships and collaboration.
 As with all the talks, participants in the room were very engaged, asked questions, and discussed various points. Aragon was asked about career paths and the backgrounds of those in the MS data science program; she said there were forty students in the first cohort and that it was a very heterogenous class, with people from many disciplines. The ethnography work has been discussed in a paper by Tanweer, Fiore, and Aragon. I hope the slides for this talk are released! There was a lot in it that I have not captured here.
As with all the talks, participants in the room were very engaged, asked questions, and discussed various points. Aragon was asked about career paths and the backgrounds of those in the MS data science program; she said there were forty students in the first cohort and that it was a very heterogenous class, with people from many disciplines. The ethnography work has been discussed in a paper by Tanweer, Fiore, and Aragon. I hope the slides for this talk are released! There was a lot in it that I have not captured here. 

The "organization envy," as one person in the room put it, continued with Rob van Nieuwpoort's talk on the Netherlands eScience Center. The Netherlands eScience center receives 5.4M€/year in permanent funding.
 Their responsibilities is demand-driven for all sciences; competition for funding and services is within disciplines, not between disciplines. They fund path-finding projects; this program is similar to UW's incubator projects program. They also receive in-kind funding for eScience research engineers; these are broadly oriented scientists.
Their responsibilities is demand-driven for all sciences; competition for funding and services is within disciplines, not between disciplines. They fund path-finding projects; this program is similar to UW's incubator projects program. They also receive in-kind funding for eScience research engineers; these are broadly oriented scientists.The eScience Center recognized early on that they wanted to give research engineers career paths; they offer three different paths: managerial, technical, and research. Asked by Katz whether research engineers have to have academic appointments, van Nieuwpoort stated that some researcher engineers do have academic appointments, but not all do. Vinju asked about educational opportunities, to which the answer was that yes, there are educational opportunities, including workshop and other training; this topic came up again a bit later.
They foster a collaborative rather than a competitive environment, with their engineers fully integrated into the scientific work, and domain scientists recognized for their contributions to software development. Research software engineers are coauthors on science papers to which they have contributed, and when software methods published, domain scientists are recognized with coauthorship.
Returning to education, van Nieuwpoort stated that research software engineers like learn, so the eScience Center keeps them challenged and learning with courses, hackathons, and sprints, and by switching disciplines and technologies.
Through eStep, an eScience technology platform, the eScience Center serves the 99% of
 scientists in the Netherlands that aren't at the eScience Center. eSTEP goals are to prevent fragmentation and duplication; to promote exchange and reuse of best practices; to represent NLeSC's expertise and knowledge, and to improve the science state of art with fundamental science research. There are key expertises used in many projects and projects use number of methodologies. NLeSC generalizes software for use in eSTEP; they find or develop state of the art and "best of breed" technologies and software matching their expertise areas that can be made generic and overarching and integrate that technology into eSTEP.
scientists in the Netherlands that aren't at the eScience Center. eSTEP goals are to prevent fragmentation and duplication; to promote exchange and reuse of best practices; to represent NLeSC's expertise and knowledge, and to improve the science state of art with fundamental science research. There are key expertises used in many projects and projects use number of methodologies. NLeSC generalizes software for use in eSTEP; they find or develop state of the art and "best of breed" technologies and software matching their expertise areas that can be made generic and overarching and integrate that technology into eSTEP.Sustainability is important to them, as is preventing duplication and fragmentation; they seek to build software that is worth sustaining and enforce software engineering best practices
 . They use Software Carpentry and Data Carpentry to educate their partners, maintain a knowledge base, and (be still, my heart!) offer a searchable software repository. And more! Slides (PDF)
. They use Software Carpentry and Data Carpentry to educate their partners, maintain a knowledge base, and (be still, my heart!) offer a searchable software repository. And more! Slides (PDF)
Of course there was discussion (and funding envy, too); Kevin Crowston pointed out that permanent funding, as Rob's eScience center has, solves a lot of issues. After a short break, we worked together (all of us in the same Google document, which was a little wild) on the Manifesto, sometimes tweeting out comments and questions, up until lunch.

 After lunch, we went into breakout sessions; these included sessions on future research questions, the research software engineering handbook, and the Force11 software citation suggestions. After working in these breakouts, we reconvened to share and discuss the progress that was made, breaking only for dinner at 6:00 PM because we had to.
After lunch, we went into breakout sessions; these included sessions on future research questions, the research software engineering handbook, and the Force11 software citation suggestions. After working in these breakouts, we reconvened to share and discuss the progress that was made, breaking only for dinner at 6:00 PM because we had to.A very busy, exciting, interesting, informative, and productive day!
-
The day started with a quick discussion about the afternoon; it is traditional for Schloss Dagstuhl seminars that Wednesday afternoons involve a social activity. It was determined on Tuesday that the activity was to be a hike some distance away from Dagstuhl with dinner after in another town, but several changes to these plans had to be ironed out and announced. After a few minutes spent on that, the morning session got underway and was furiously fast! This was an Open Mic, with participants having signed up while here to give short talks (ten minutes or less).
First up was Daniel Garijo on Software Metadata: Describing “dark software” in Geosciences. By "dark software," he means that which is often hidden from view. He described the current state of the art for software description in geosciences and demonstrated Ontosoft.org, a semantic registry for scientific software, which currently includes information from several geosciences resources. As Ontosoft is not domain-specific, it has the capacity to expand into other fields as well. This is a very attractive and capable site. It uses a distributed approach to software registries and depends on crowdsourcing for metadata maintenance. The resource organizes software metadata using the OntoSoft ontology along six dimensions: identify software, understand and assess software, execute software, get support for the software, do research with the software, and update the software. Slideshare
Jurgen Vinju was next with Organising a research team around the research software around the research team in software engineering: Motivation, experiences, lessons. He talked about his experiences as the group leader of the SWAT (Software Analysis and Transformation) team at Centrum Wiskunde and Informatica (CWI), the national research institute for math and computer science in the Netherlands.
 SWAT is all about the source code and supporting programmers to create more efficient, maintainable software. They work to understand and control software complexity to enable more and better tools. He made the point that research teams "prioritise for academic output which is not software." He showed UseTheSource, a resource developed by CWI with contributions from other institutes and housing open-source projects related to software language engineering and metaprogramming. This allows more efficient programming by automating tasks that are cumbersome or hard, and allows synergies between software engineers, researchers, and industry. PDF
SWAT is all about the source code and supporting programmers to create more efficient, maintainable software. They work to understand and control software complexity to enable more and better tools. He made the point that research teams "prioritise for academic output which is not software." He showed UseTheSource, a resource developed by CWI with contributions from other institutes and housing open-source projects related to software language engineering and metaprogramming. This allows more efficient programming by automating tasks that are cumbersome or hard, and allows synergies between software engineers, researchers, and industry. PDF

Dan Katz gave an overview of work done by the Force11 Software Citation Working Group; his presentation was titled Software Citation: Principles, Discussion, and Metadata. He provided
 rationales for citing software, information on the WSSSPE and Force11 groups involved in developing software citation principles and the process used to develop them, and then the six principles, which focus on the importance of software, the need to credit and attribute the contributions software makes to research and to be able to uniquely identify software in a persistent and specific way, and that citations should enable access to the software and associated information about the software that informs its use. Katz brought up many of the discussions the WSSSPE and Force11 working groups had and their determinations, such as what software to cite, how to uniquely identify software, that peer-review of software is important but not required for citation, and how publishers can help.
rationales for citing software, information on the WSSSPE and Force11 groups involved in developing software citation principles and the process used to develop them, and then the six principles, which focus on the importance of software, the need to credit and attribute the contributions software makes to research and to be able to uniquely identify software in a persistent and specific way, and that citations should enable access to the software and associated information about the software that informs its use. Katz brought up many of the discussions the WSSSPE and Force11 working groups had and their determinations, such as what software to cite, how to uniquely identify software, that peer-review of software is important but not required for citation, and how publishers can help.
 Each of the Open Mic sessions generated immediate discussion during the sessions and while the next presenter was setting up, and this session was no exception. When Katz pointed out that a common practice is to publish and cite papers about software (“software papers”), but that the Importance principle of the Force11 Working Group calls for the citation of the software itself, "on the same basis as any other research product", this was countered with a comment that people should cite software papers if the software authors have requested that method of citation. Katz stated that could be done in addition to citing to the software, as one of his slides stated. The presentation concluded with information on the next steps for the Force11 Software Citation Working Group -- to finalize the principles, and publish and circulate them for endorsement -- and the likelihood of a Software Citation Implementation Group being formed to work with institutions, researchers, publishers, and other interested parties to put the principles into practice. PDF
Each of the Open Mic sessions generated immediate discussion during the sessions and while the next presenter was setting up, and this session was no exception. When Katz pointed out that a common practice is to publish and cite papers about software (“software papers”), but that the Importance principle of the Force11 Working Group calls for the citation of the software itself, "on the same basis as any other research product", this was countered with a comment that people should cite software papers if the software authors have requested that method of citation. Katz stated that could be done in addition to citing to the software, as one of his slides stated. The presentation concluded with information on the next steps for the Force11 Software Citation Working Group -- to finalize the principles, and publish and circulate them for endorsement -- and the likelihood of a Software Citation Implementation Group being formed to work with institutions, researchers, publishers, and other interested parties to put the principles into practice. PDF The fourth Open Mic talk was by Katerena Kuksenok on Best Practices (by any other name). This interesting talk looked at
The fourth Open Mic talk was by Katerena Kuksenok on Best Practices (by any other name). This interesting talk looked at intersections of the technical, social, and cognitive aspects of software engineering in research, and asked how the available community and skill resources could be leveraged. brought together various elements brought up through the workshop so far, including different roles that had been identified, the need for software engineers to learn from scientists just as we hope researchers learn software engineering practices,
intersections of the technical, social, and cognitive aspects of software engineering in research, and asked how the available community and skill resources could be leveraged. brought together various elements brought up through the workshop so far, including different roles that had been identified, the need for software engineers to learn from scientists just as we hope researchers learn software engineering practices,  and overcoming communications barriers. She referred back to a comment Mike Croucher had made in his talk on Monday, agreeing that software engineers should "do CS/SE with people not at them!" PowerPoint
and overcoming communications barriers. She referred back to a comment Mike Croucher had made in his talk on Monday, agreeing that software engineers should "do CS/SE with people not at them!" PowerPointAfter Kuksenok's talk, I presented Restoring reproducibility: Making scientist software discoverable. This presentation was a quick overview of the ASCL, its history and a few of the changes to our infrastructure, the lessons we learned from
 looking at what other astro code registries and repositories had done and what we did with those lessons, and some of the impact we have on the community. As with every other session, there was intermittent discussion, questions asked and answered, and conversation on the topic as I headed back to my chair and the next speaker set up. PowerPoint PDF
looking at what other astro code registries and repositories had done and what we did with those lessons, and some of the impact we have on the community. As with every other session, there was intermittent discussion, questions asked and answered, and conversation on the topic as I headed back to my chair and the next speaker set up. PowerPoint PDFRobert Haines was up next with A Short* History of Research Software Engineers in the UK (*and probably incomplete). Before there were Research Software Engineers (RSE), there were RSEs going by other names, such as Post Doc and Research Assistant. These were the people in the lab who could code, and
 fell "foul of publish or perish" because they were writing code rather than papers. RSEs might also have been hiding as those working in high performance computing or as a research group admin. He is an example of someone who has always done RSE work, though was not called an RSE until fairly recently. It was at a Software Sustainability Institute Collaborations Workshop in 2012 that there was a call to arm to recognize the
fell "foul of publish or perish" because they were writing code rather than papers. RSEs might also have been hiding as those working in high performance computing or as a research group admin. He is an example of someone who has always done RSE work, though was not called an RSE until fairly recently. It was at a Software Sustainability Institute Collaborations Workshop in 2012 that there was a call to arm to recognize the  contributions of those who write code rather than papers and are not purely researchers. They decided they needed a name, to unionize, and a policy campaign. He described the current environment, both the challenges and the positives, and shared that many people want to work in this field. Yes, discussion broke out in this session, too! It was remarkable how engaged everyone at the workshop was, and how often and easily discussion took place. PDF
contributions of those who write code rather than papers and are not purely researchers. They decided they needed a name, to unionize, and a policy campaign. He described the current environment, both the challenges and the positives, and shared that many people want to work in this field. Yes, discussion broke out in this session, too! It was remarkable how engaged everyone at the workshop was, and how often and easily discussion took place. PDF Dan Katz made a very brief presentation and instigated more discussion on career paths when Robert Haines was finished, then after a brief coffee break, the morning Open Mic session continued with Ralf Lämmel's presentation intriguingly called Making a failing project succeed?! about the 101Companies project. He called 101Companies a software chrestomathy, from chresto, meaning "useful" and mathein, meaning "to learn." He shared other chrestomathies, such as the Hello World Collection and the Evolution of a Haskell programmer. (One of the previous links will lead you to a song about a popular beverage.) 101Companies is a resource for learning
Dan Katz made a very brief presentation and instigated more discussion on career paths when Robert Haines was finished, then after a brief coffee break, the morning Open Mic session continued with Ralf Lämmel's presentation intriguingly called Making a failing project succeed?! about the 101Companies project. He called 101Companies a software chrestomathy, from chresto, meaning "useful" and mathein, meaning "to learn." He shared other chrestomathies, such as the Hello World Collection and the Evolution of a Haskell programmer. (One of the previous links will lead you to a song about a popular beverage.) 101Companies is a resource for learning  more about software, for comparing technologies, for programming education, and can serve as "a playground for student projects." He discussed some of the challenges the project is having and some of the ways in which it is succeeding. PDF
more about software, for comparing technologies, for programming education, and can serve as "a playground for student projects." He discussed some of the challenges the project is having and some of the ways in which it is succeeding. PDFThe last Open Mic talk of the morning was by Ashish Gehani giving a quick overview of his work on software, including software to make data more manageable, particularly the
The last agenda item for the morning was to discuss the manifesto that is one of the required
 outputs for this workshop. This discussion was led by James Howison, who shared the link for the Google Doc that was to become the manifesto, and which was discussed and created in tandem (and wild abandon) by many in the room du
outputs for this workshop. This discussion was led by James Howison, who shared the link for the Google Doc that was to become the manifesto, and which was discussed and created in tandem (and wild abandon) by many in the room du ring the time remaining before lunch. The manifesto is our public declaration, our own call to action. Our work is only beginning at Schloss Dagstuhl; we must put what we have discussed here into practice. We shared other manifestos (manifesti!), determined authorship as opt-in (by adding our names to the author list), and talked about but did not determine where this might be published. I found the creation of this document interesting and inspiring, very much in line with the philosophy of "be the change you want to see in the world."
ring the time remaining before lunch. The manifesto is our public declaration, our own call to action. Our work is only beginning at Schloss Dagstuhl; we must put what we have discussed here into practice. We shared other manifestos (manifesti!), determined authorship as opt-in (by adding our names to the author list), and talked about but did not determine where this might be published. I found the creation of this document interesting and inspiring, very much in line with the philosophy of "be the change you want to see in the world."

After getting a good start on the manifesto, we broke for a longer than usual lunch period, after which some took a long hike with a lakeside stop for a refreshing beverage, and some did other things. I took a much-needed nap and then noodled around for a bit in the music room, a lovely large, long room with wonderful acoustics and a recently-tuned grand piano, two guitars, a cello, and a violin available. (I discovered later in the week that the violin case also holds a kazoo.)
a lovely large, long room with wonderful acoustics and a recently-tuned grand piano, two guitars, a cello, and a violin available. (I discovered later in the week that the violin case also holds a kazoo.)  Scores for solo and ensemble music are stocked in a room at one end of the music room, the (small) door to which is watched over by cherubs. Most of the Schloss is modern in appearance; this is one of the few rooms that reveals the building's history. I found plenty of music to amuse myself with, including a collection of Bach preludes and fugues from the WTC apparently edited by Bartók and in what to me was a confusing order, and Beethoven sonatas that at one time I knew how to butcher. Others reported having taken shorter walks than the one that was organized, listening to podcasts, trying out the bicycles available for guests, and also napping.
Scores for solo and ensemble music are stocked in a room at one end of the music room, the (small) door to which is watched over by cherubs. Most of the Schloss is modern in appearance; this is one of the few rooms that reveals the building's history. I found plenty of music to amuse myself with, including a collection of Bach preludes and fugues from the WTC apparently edited by Bartók and in what to me was a confusing order, and Beethoven sonatas that at one time I knew how to butcher. Others reported having taken shorter walks than the one that was organized, listening to podcasts, trying out the bicycles available for guests, and also napping.As you have likely surmised by now, the Twitter hashtag for this event was
#dagstuhleas, and the Twitter feed offers more pictures and information about this workshop.
